Tech Corner December 12, 2023
Using LLMs confidently in financial services workflows



Introducing tools powered by large language models (LLMs) into your workflows presents a new opportunity to dive deeper into your data. The capability to instantly generate detailed summaries of quarterly reports or automate the review of lengthy Confidential Information Memos can be a game changer for your team’s operational efficiency and ability to service more clients.
Conversations about LLMs and generative AI often touch on approaches to maintain data privacy and security standards, particularly in financial services and for enterprise use cases. Another equally important topic is accuracy and traceability. LLMs can occasionally generate incorrect responses, or “hallucinations,” and it’s important that any product using LLMs incorporate layered strategies to reduce hallucinations. If you’re integrating LLMs into your critical workflows, you need to ensure the information is correct and can stand up to regulatory scrutiny. Being confident in the data output from an LLM-powered product is essential.
Taking the time to manually read every document to double-check every answer’s accuracy defeats the purpose of using LLMs in your workflow. So how do you trust that the responses you’re getting are correct? Data scientists researching LLMs and training models are exploring multiple paths to build confidence in LLM outputs:
- Model explainability: Mechanisms used to explain how a model reasoned over and arrived at an answer, including analyzing the underlying weights and features.
- Confidence scoring: Scores assigned and provided alongside the model’s response to inform the user whether the response can be taken at face value or requires more interrogation.
- Attribution: Providing the source for the response—where in a document (or collection of documents) the LLM found an answer.
How Alkymi is centering traceability in our LLM product development
In building our LLM-powered features and tools, our focus is on the needs of our customers, who are primarily in financial services. Data extracted from documents using LLMs needs to be accurate, and it also needs to be traceable. Every piece of actionable data needs to be verified and able to be traced back to the source document, automatically.
Model explainability is useful but doesn’t provide traceability. Similarly, confidence scores provide information to help you gauge your trust in the response, but they’re still not easily verifiable. Attribution is a natural fit to provide traceability for financial services use cases, since it provides a direct link between the LLM's response and the source in the document.
Providing a linked source, or multiple sources, alongside the LLM’s answer to a user’s question allows them to easily find the supporting data for a response without needing to find it independently. Answers can be verified as needed without extensive manual review, whether to confirm the accuracy of the tool and build confidence in its responses or for auditing purposes. Being able to instantly highlight where an answer came from in a long document allows users to validate the output in real-time and provides a clear audit trail.
For example, when reviewing information on a potential investment, you might want to quickly find and synthesize a company’s projected financials into a short summary you can share with your team. Alkymi’s LLM-powered tools can generate that answer and then highlight exactly where in the source document the response originated from.
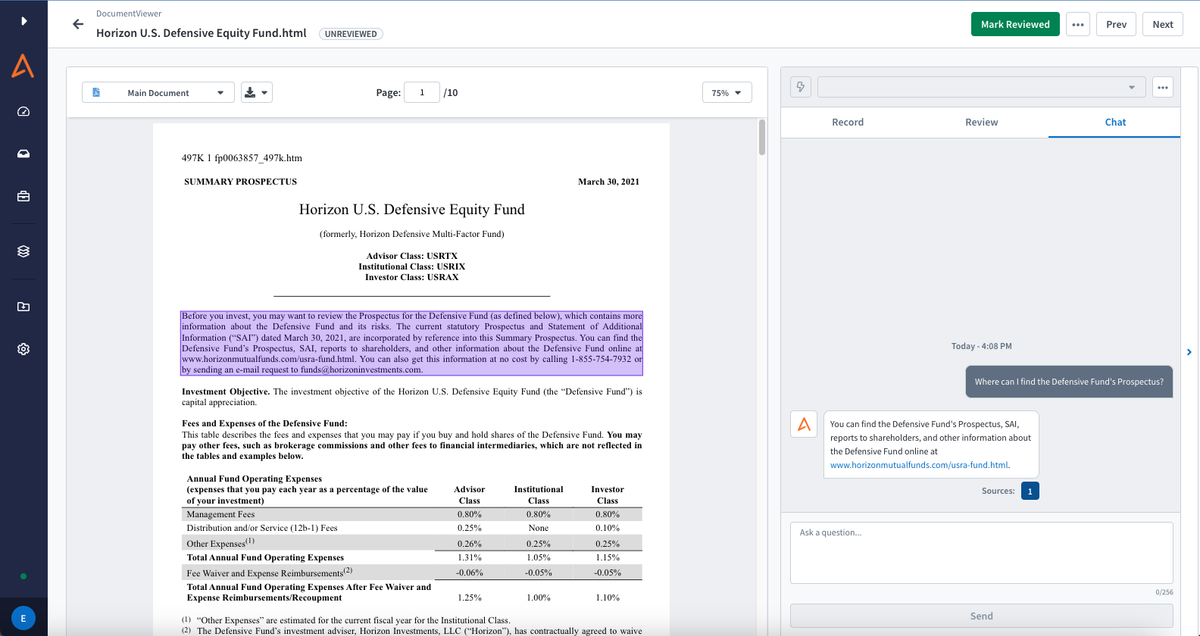
If you’re looking to introduce any tool utilizing large language models to be useful in financial services, being able to trust its output should be non-negotiable. Our natural instinct is to double-check where the data came from and match it against the original document. An intentionally built tool for financial services data should do that for you, so validating even generative AI can happen in an instant.
Read more about the theory behind our approach in our Data Science Room.
More from the blog

Modern Capital Podcast: Harald Collet: Who Wrote That Spreadsheet Formula?
by Maria OrlovaListen as Alkymi CEO, Harald Collet, shares the journey behind Alkymi and his perspective on the future of investment operations.

Alkymi Is Transforming Private Markets Investment Operations with Enterprise AI and Workflow Automation: Mid-Year Review
by Maria OrlovaAlkymi's mid-year review highlights AI innovation, private markets automation, document retrieval, enterprise workflows, customer growth, partnerships & awards

The Next Generation of Agentic AI Document Retrieval for Private Markets
by Keerti HariharanExplore the next generation of Automated Document Retrieval that uses APIs, agentic AI, and human oversight to streamline investor portal workflows.