Product Updates June 30, 2022
Alkymi Product Update: Helping You Easily Do More




At Alkymi, we take enablement seriously. We’re always striving to create tools that will help you cut through any volume of unstructured data to quickly and easily take the actions most relevant to the work you’re doing. This month’s updates are all about improving the tools you’re already using so you can do more faster, easier, and with greater accuracy than ever before. Take a look at what’s new in Alkymi in June.
More ways to action high-volume data
Everyone knows that Alkymi Data Inbox can extract huge amounts of data from very data-rich documents. What happens, though, if there’s a single data exception buried amidst hundreds of rows and dozens of columns of clean, structured data? Good news: exception handling for data-heavy documents just got a major overhaul.
You can now easily pinpoint any validation errors in a Pattern right in Document Viewer or in the Subschema Field link. The drop down menu will show which records have validation issues with exact precision.
The updates make it faster and easier to create instantly actionable data - that means even greater data accuracy and time savings for Data Inbox users.

More data targeting options, greater accuracy
One of the bigger challenges with unstructured data processing is that the data that’s most meaningful to you can appear anywhere within the document’s bounds. That’s why we at Alkymi work so hard to empower businesses with intelligent data processing technology that’s flexible and adjustable based on your needs.
That customizability grew even more with this update - you can now define Sections so that they refine the “search area” of a Tool. With the ability to define Sections in any combination of a top, bottom, right, or left boundary, you’re now empowered to extract data from hard-to-reach areas of documents.
For example, you may be processing documents that have multiple areas within it that specify a “name”, but you actually only need the name that’s included in the customer information section in the header - not any of the others. Using Sections, you can hone in on the correct part of the document and target the single data piece you’re looking for, speeding up your workflow and helping you faster and more precisely create actionable data.
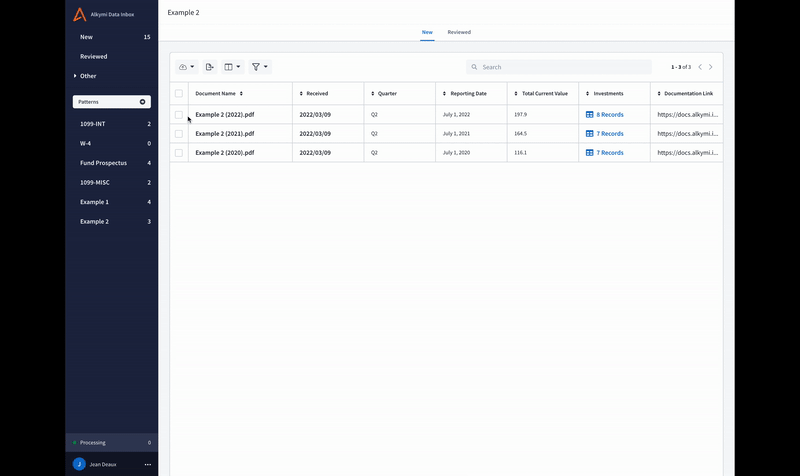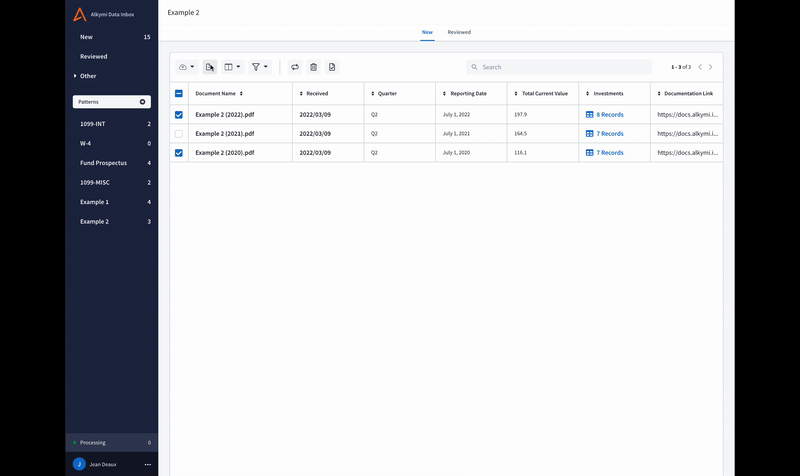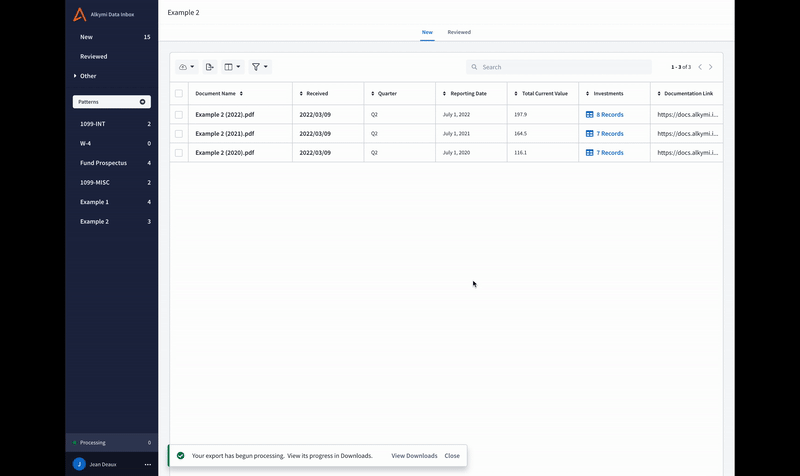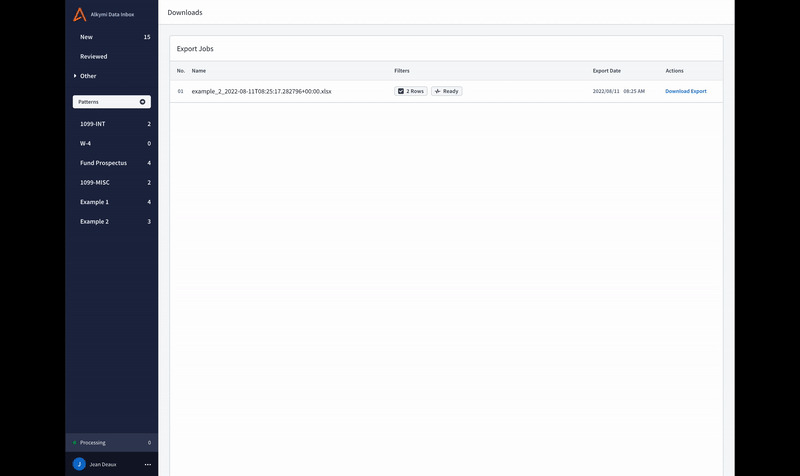
Downloads: referenceable, repeatable, and bigger than before
It used to be that if you wanted to generate another download of data like you’ve exported before, you’d have to go through the process of filtering through the Data Inbox each time. Not anymore! You can now visit the Downloads Page to view historic downloads – and best of all – review the exact filtering criteria used to generate the export. This page is shared across all Data Inbox users in your organization, so if someone else in the company wants to export the same file (or type of file) you did earlier that day, week, month, or year, it’s easily referenceable and repeatable for them to do.
It wasn’t just organization and repeatability we improved. The Downloads Page got an overhaul in overall capability, too, making it possible to easily download exports with tens of thousands of rows.
3 integrations you love
We know a lot of you are using Salesforce, Microsoft Power Automate, and Zapier in the course of your workflow, and are fueling workflows in those apps with structured data from Data Inbox. Now you can leverage those tools even more with the intelligent document extraction and workflow benefits of Alkymi. Visit our updated Integrations Page to see all 3 integrations as well as information about how to set up and use each one.

Alkymi is for those ready to do more, easily
Are you ready to offload the tedium - tasks of data collection, extraction, normalization, and integration - to a flexible data automations solution that adapts to your needs? Give Alkymi a try. Get started today with our free trial.
More from the blog

Private Credit: The Reckoning Is Here, And the Regulators Have Arrived
by John Park, Director of Professional ServicesThe private credit market is maturing. Discover how growing regulatory expectations are reshaping operations, risk management, and reporting.

How AI Agents Turn Extracted Data into Portfolio Insights
by Nate Byerly, Sr. Solutions ArchitectFrom investment documents to on-demand portfolio analysis. See how Alkymi delivers trusted answers in minutes.

Global Fortune 500 Asset Manager Selects Alkymi for Private Credit Operations
by Harald Collet, CEOSelected by a leading added allocator to automate private credit operations and transform unstructured documents into workflow-ready investment data..