Tech Corner October 3, 2024
Speed up CIM review with LLMs




High-value deals require fast, data-driven decisions.
Private equity firms and investment managers spend hundreds of hours manually combing through unstructured Confidential Information Memorandums (CIMs) and offering memos, extracting key data to assess a company’s performance before making an investment decision.
To get an edge on your competition, you need to be able to review deals with speed and precision. That’s where large language models come in.
LLMs can transform your firm’s deal review workflows so you can act on critical deals ahead of your competitors. What does integrating LLMs into your deal analysis look like?
Using LLMs, we built a CIM workflow at Alkymi that reduced deal cycle analysis time for one of our customers from 90 to 30 days.
An average CIM can consist of 100+ PDF pages or PowerPoint slides and takes significant time to review closely. Leveraging LLMs within Alkymi’s automated data workflows, we can automatically parse unstructured CIMs, extracting key metrics such as EBITDA, margins, year on year revenue growth rates, market positioning, and more. Extracted data is transformed and validated according to each customer’s requirements. The verified data is then delivered to downstream decisioning platforms like DealCloud, to data warehouses, to CRMs like Salesforce, or to dashboards where company performance can be visualized and benchmarked against industry peers.
Here’s how we designed our CIM workflow at Alkymi:
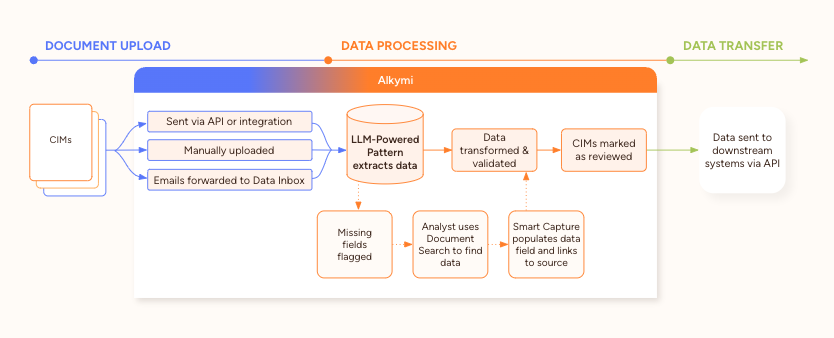
Step 1: Using generative AI and LLM-powered tools within our platform, we built a set of questions to be systematically asked of each CIM sent through the workflow.
Step 2: The answer to each question needed to come from specific sections of each CIM. Alkymi’s platform allows us to add page filtering rules to each question asked of the LLM, to ensure answers are pulled only from designated sections (for example, a question asking about the company’s EBITDA could be built to pull an answer only from the “Financial Overview” section of the document). Using this method, the vast majority of data fields are populated automatically, with 100% traceability, so analysts can easily verify the source of each answer within the document.
Step 3: If an answer isn’t found in a particular section, our platform flags it, so the analyst team knows which field needs further review.
Step 4: An analyst then searches for the value in the document, using the document viewer within our platform. If the answer is in the document but outside of its normally designated section (for example, if the EBITDA is instead listed in the “Company Snapshot” page), they are then able to quickly locate it.
Step 5: Next, they use our Smart Capture tool to populate the corresponding data field and link it back to where the value was found in the document, without the need to retype it manually.
Step 6: Once all the data is extracted and organized to the correct fields, our platform automatically validates and transforms it to the correct format, according to each customer's requirements. Each answer can be traced back to its source in the CIM.
Step 7: Lastly, the clean, validated data is sent directly to their deal sourcing platform, dashboard, or other downstream system via API, with no manual input required.
Utilizing LLMs within an automated CIM workflow not only expedites the deal sourcing process, it also empowers you to capture more data, so you can better identify high-value deals with confidence and speed. Gain a competitive edge with deeper insights into your data, leading to better valuations, more strategic deal selection, and faster time to value for your firm.
Schedule a demo to see how Alkymi can help your firm automate data processing for CIMs and offering memorandums.
More from the blog

Data Management Insight Awards USA 2026
by Maria OrlovaAlkymi is shortlisted for three Data Management Insight Awards USA 2026 categories, recognizing its AI-powered data automation platform.

The FTF News Technology Innovation Awards 2026
by Maria OrlovaAlkymi wins Best Data Integration Solution at the FTF News Technology Innovation Awards

Private Credit: The Reckoning Is Here, And the Regulators Have Arrived
by John Park, Director of Professional ServicesThe private credit market is maturing. Discover how growing regulatory expectations are reshaping operations, risk management, and reporting.